在众多 AI 排行榜中,ChatGPT 依然位居榜首,但竞争者紧随其后
如何判定当前最强大的人工智能模型?看看排行榜就知道了。
AI模型的社区编制排行榜近几个月来在线上的受欢迎程度激增,为我们提供了一个实时的窗口,洞察主要科技巨头在人工智能领域的角逐。
各个排行榜记录了哪些 AI 模型在执行某些任务上最为领先。AI 模型本质上是一组包裹在代码中的数学公式,旨在实现特定的目的。
像谷歌的 Gemini(之前的 Bard)和巴黎初创企业 Mistral AI 的 Mistral-Medium 这样的新入场者,激起了 AI 社区的热情,并在排行榜的顶端争夺地位。
然而,OpenAI 的 GPT-4 仍然占据主导地位。
斯坦福大学计算机科学专业的博士生 Ying Sheng 是“Chatbot Arena”排行榜的共同创建者,他表示:“人们在意的是技术的最前沿。我认为人们其实更喜欢看到排行榜持续变化。这说明比赛仍在继续,还有进步的空间。”
排名是基于对 AI 模型的能力测试得出的,这些测试旨在搞清楚 AI 通常有什么能力,以及哪个模型可能在特定应用,例如语音识别上,最为得心应手。这些测试,有时候也被称作基准测试,通过例如 AI 发声听起来有多接近人声,或 AI 聊天机器人回应的人性化程度等指标,来测量 AI 的性能。
随着人工智能不断发展,对这些测试的不断改进也同样至关重要。
斯坦福大学人本中心人工智能研究所的研究总监 Vanessa Parli 表示:“这些基准测试不是完美的,但就目前而言,这是我们评估系统的唯一方法。”
该研究所发布的斯坦福人工智能指数年度报告,追踪了各类度量指标下AI模型随时间的技术性能。据Parli所述,去年的报告调研了50个基准,但只包含了20个。今年,报告将淘汰一些过时的基准,以便聚焦于更新、更综合的基准。
通过排行榜,我们还能窥见正在开发的模型的数量。Hugging Face建立的开放LLM[大型语言模型]排行榜,一个开源机器学习平台,截至2月初已经评估并排名了超过4200个模型,这些均由社区成员提交。
这些模型参与七项关键的基准测试,这些测试旨在评估它们的各类能力,比如阅读理解和数学解题能力。评价过程包括出小学数学和科学题目,测试模型的常识推理能力,以及衡量它们传播错误信息的倾向。有些测试提供选择题形式,有些则要求模型基于提示自主产生答案。
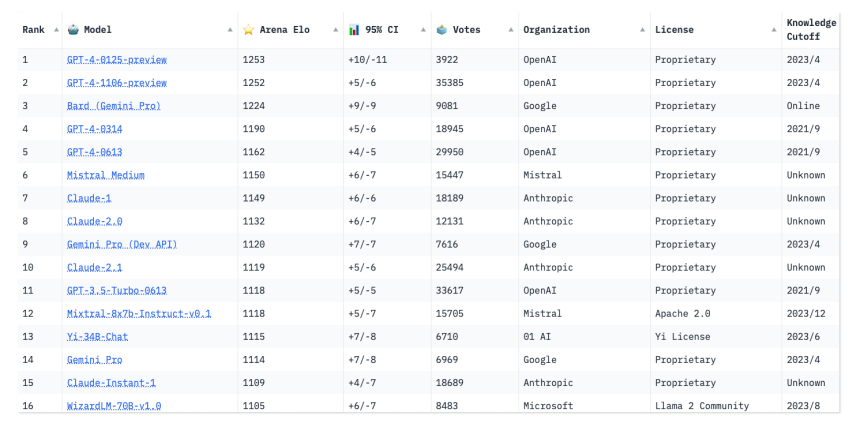
在LMSYS聊天机器人竞技场排行榜上,可以看到OpenAI的ChatGPT-4排在前列,紧随其后的是Google的Gemini。via LMSYS
访客可以查看每个模型在特定基准测试上的具体表现,以及它们的平均总分。到目前为止,还没有模型在任何基准上达到满分100分。由旧金山初创企业Abacus.AI新开发的AI模型Smaug-72B,成为了第一个平均得分突破80分的模型。
许多大型语言模型已经在此类测试中超过人类的基准水平,研究人员称这现象为“饱和”。Hugging Face的联合创始人兼首席科学官Thomas Wolf表示,这通常发生在模型能力提升到超越特定测试的程度,就像学生从初中升入高中逐渐超越之前的学习阶段;或者模或者当模型已经记住了如何回答某些测试问题时,这个概念叫做“过拟合”。