提示工程在大语言模型中应用的必要性
下面主要介绍了提示工程的基本理念,及其如何提升大型语言模型(LLM)的性能…
LLM的接口:大型语言模型如此火热的一个重要原因就是其文本到文本的接口实现了极简的操作体验。在过去,利用深度学习解决任务通常需要我们至少对某些数据进行微调,以教会模型如何解决对应任务。然而,大部分模型都只是在特定任务上有专业深度。但现在,得益于LLM的出色的上下文学习能力,我们可以通过一个文本提示就解决各种问题。原本复杂的问题解决过程已经被语言抽象化!
“提示工程是一门相对较新的学科,主要聚焦于为各种应用和研究主题高效地利用语言模型进行开发和优化提示。” – 引自[1]
什么是提示工程?LLM的简单易用让更多人可以使用它。你不需要是数据科学家或机器学习工程师就可以使用LLM,只需理解英语(或你选择的任何语言),你就能用LLM解决相对复杂的问题!但是,当让LLM来解决问题时,结果往往在很大程度上取决于我们给模型的文本提示。由此,提示工程(即使用经验来测试不同的提示以优化LLM性能的方法)已经变得非常流行,并且有着很大的影响,从而使我们找到了许多技术和最佳实践。
如何设计提示:设计LLM的提示有很多方法。但是,大部分的提示策略有着几个共同的要点:
– 输入数据(Input Data):LLM需要处理的实际数据(比如,需要翻译或分类的句子,需要总结的文档,等等)。
– 示例(Exemplars):在提示中包含的正确输入输出对的实例。
– 指令(Instruction):模型预期产出的文字说明。
– 标签(Indicators):在提示中创建结构的标签或格式元素。
– 上下文(Context):在提示中给予LLM的任何额外信息。
在以下的图示中,我们举例说明了如何将以上提到的所有提示元素融合在单一的句子分类提示中。

上下文窗口:在预训练期间,LLM看到的都是特定长度的输入序列。在预训练中,我们选择这个序列长度作为模型的“上下文长度”,这也就是模型所能处理的最大序列长度。如果给出的一段文字明显超过了这个预设的上下文长度,模型可能会做出不可预知的反应,输出错误的结果。但实际上,有一些方法—比如自我扩充[2]或位置插值[3]—可以被用来扩展模型的上下文窗口。
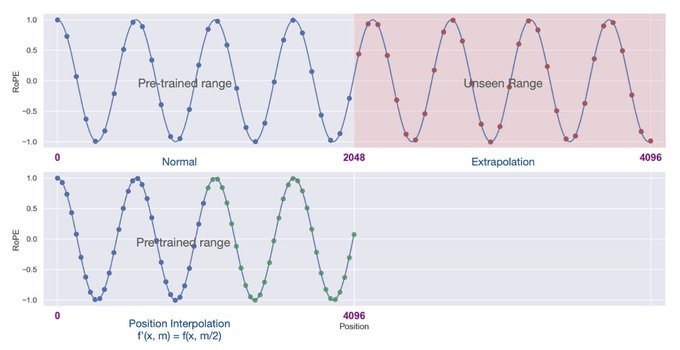
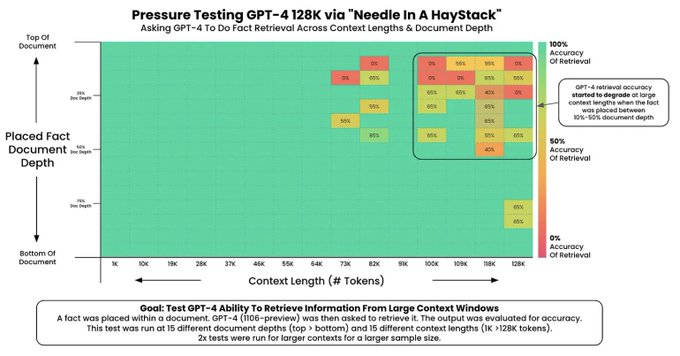
最近关于LLM的研究强调了创建长的上下文窗口,这使得模型在每个提示中能处理更多的信息(如,更多示例或更多的上下文)。但是,并非所有LLM都能够完美的对其上下文信息进行处理!一个LLM可以在长的上下文窗口中处理信息的能力通常通过“大海捞针测试”[4]来评估,这种测试会:
1. 在上下文中嵌入一个随机事实。
2. 要求模型找到这个事实。
3. 在各种上下文长度和上下文中事实的位置上重复这个测试。
这种测试可以生成一张像下面的图片(来源 [4]),在这张图中我们可以容易的发现上下文窗口所存在的问题。
我的提示工程策略:提示工程的细节会因为所使用的模型而有所差异。但是,有一些通用的原则也可以作为提示工程过程中的指导:
– 实证法:提示工程的第一步就是设定一个可靠的评估你的提示的方式(如,通过测试案例,人类的评估,或LLM作为评判)以便简单地衡量对提示的修改。
– 由简入繁:首次尝试的提示应应尽可能简单,而不是一开始就尝试复杂的链式思考提示或其他特殊的提示技术。最初始的提示应该简单,然后逐渐增加复杂程度,同时衡量性能的变化,来判断是否需要增加额外的复杂性。
– 尽可能具体和直接:尽力消除提示中的模糊性,在说明预期输出时尽量简洁、直接、具体。
– 加入示例:如果描述预期产出比较困难,试着在提示中加入示例。示例提供预期输出的具体案例,可以消除模糊性。
– 尽可能避免复杂性:复杂的提示策略有时是必要的(例如,为了解决多步推理问题),但是我们在采取这种方法前要三思。采取实证的观点,并使用已经建立的评价策略真正判断是否必要加入这种复杂性。
总结上述所有,我的个人提示工程策略是i)投入到一个好的评价框架,ii)从一个简单的提示开始,并且iii)按需慢慢添加复杂性以达到所需的性能水平。。

注释:
[1] https://promptingguide.ai
[2] https://arxiv.org/abs/2401.01325
[3] https://arxiv.org/abs/2306.15595
[4]https://github.com/gkamradt/LLMTest_NeedleInAHaystack