Tokenization(分词标记化)
各位好,今天我们要探讨大型语言模型(LLM)中的分词技术。遗憾的是,分词在当前顶尖的LLM中是一个比较复杂且棘手的部分,但理解它的某些细节非常必要,因为很多人将LLM的一些缺点归咎于神经网络或其他显得神秘的原因,实际上这些问题的源头往往是分词技术。
之前:基于字符的分词
那么什么是分词呢?其实在我们之前的视频[从零开始构建GPT]中,我们已经讲过分词了,但那只是一种非常简单且原始的字符级别形式。如果你去看那个视频的[Google colab]页面,你会发现我们使用的是我们的训练数据([莎士比亚作品],它在Python中只是一个很长的字符串:
First Citizen: 在我们继续之前,请听我说。All: 说吧,说吧。First Citizen: 你们都决心宁愿死也不愿饿死吗?All: 决心的。决心的。First Citizen: 首先,你们知道Gaius Marcius是人民的头号敌人。All: 我们知道,我们知道。
但是,我们如何把字符序列输入到语言模型中去呢?我们这样做的第一步是构造一个词汇表,这个表包括了我们在整个训练数据集中找到的所有不同字符:
“`python# 这是文本中出现的唯一字符chars = sorted(list(set(text)))vocab_size = len(chars)print(”.join(chars))print(vocab_size)# !$&’,-.3:;?ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz# 65“`
紧接着,我们会创建一个查找表,用于将单个字符和整数字之间进行转换,这个查找表基于上面列出的词汇。这个查找表实际上是一个Python字典:
“`pythonstoi = { ch:i for i,ch in enumerate(chars) }itos = { i:ch for i,ch in enumerate(chars) }# 编码器:接收一个字符串,并输出对应的整数列表encode = lambda s: [stoi[c] for c in s]# 解码器:接收一个整数列表,并还原回字符串decode = lambda l: ”.join([itos[i] for i in l])print(encode(“hii there”))print(decode(encode(“hii there”)))# [46, 47, 47, 1, 58, 46, 43, 56, 43]# hii there“`
我们将序列转换为整数之后,会看到每个整数都作为索引在一个二维的可训练嵌入矩阵中使用。由于词汇表的大小为`vocab_size=65`,因此这个嵌入矩阵也有65行:
“`pythonclass BigramLanguageModel(nn.Module):def __init__(self, vocab_size):super().__init__()self.token_embedding_table = nn.Embedding(vocab_size, n_embd)def forward(self, idx, targets=None):tok_emb = self.token_embedding_table(idx) # (B,T,C)“`
在这里,“integer”提取了嵌入表中的一行,而这行就是代表该标记(token)的向量。接着,这个向量作为相应时间步的输入进入变换器(Transformer)。
使用字节对编码(BPE)算法的”字符块”进行标记化
这对于一个初级的字符级别语言模型来说已经足够好了。但在实践中,最先进的语言模型会采用更复杂的方案构建标记词汇表。这些方案并不是在字符级别上工作,而是在字符块级别上。这些字符块词汇表是通过使用像字节对编码(BPE)这类算法构建的,我们将在下文详细解释这种方法。
转向这种方法的历史发展,OpenAI在2019年发表的GPT-2论文,标题为《语言模型是无监督多任务学习者》,使得字节级BPE算法在语言模型的标记化中流行起来。阅读本文2.2节关于“输入表征”,了解他们对这一算法的描述和动机。在本节末尾,你将看到它们提到:
词汇量已经扩展到了50,257。我们还将上下文大小从512增加到了1024个标记,并且使用了更大的批次大小512个。
回想一下在变换器(Transformer)的关注(attention)层,每一个标记(token)都是对之前序列中的有限数量标记进行关注。论文提到,GPT-2模型的上下文长度是1024个标记,比GPT-1的512个有所提高。换句话说,标记是作为语言长期记忆模型(LLM)输入的基本单元。标记化是将Python中的原始字符串转换为标记列表的过程,反之亦然。举一个其他的流行例子来展示这种抽象概念的无处不在,你如果查看[Llama 2]的论文,同样搜索“标记”,你会得到63处提及。就比如说,论文声称他们在两万亿个标记上训练等等。
在我们深入探讨实现细节之前,先简要探讨一下为什么我们需要深入了解令牌化过程。令牌化是LLMs中许多奇异现象的核心,我建议大家不要轻视它。很多看似与神经网络结构有关的问题,实际上都源自于令牌化。这里列举几个例子:
- 为什么LLM无法正确拼写单词?
- 为什么LLM无法完成如字符串反转这样的简单字符串处理任务?
- 为什么LLM在处理非英语语言(比如日语)时表现不佳?
- 为什么LLM在进行简单算术运算时表现不佳?
- 为什么GPT-2在Python编程时遇到了额外的困难?
- 为什么我的LLM在遇到”<|endoftext|>”字符串时突然停止工作?
- 我收到的关于“尾随空格”的奇怪警告是什么意思?
- 当我询问关于”SolidGoldMagikarp”时,为什么LLM会崩溃?
- 为什么我应该更倾向于使用YAML而不是JSON来与LLMs交互?
- 为什么LLM实际上并不是真正的端到端语言模型?
- 痛苦的根源究竟是什么?
我们将在视频的最后回到这些话题。
接下来,我们来加载这个[令牌化在线工具]。这个在线工具的优势在于,令牌化过程是在您的网络浏览器中实时进行的,您可以轻松地在输入框输入文本字符串,并立即在右侧看到令牌化的结果。页面顶部显示我们目前使用的是
gpt2令牌化器,我们可以看到示例中的字符串正在被分解成300个令牌。这些令牌以不同的颜色清晰展示: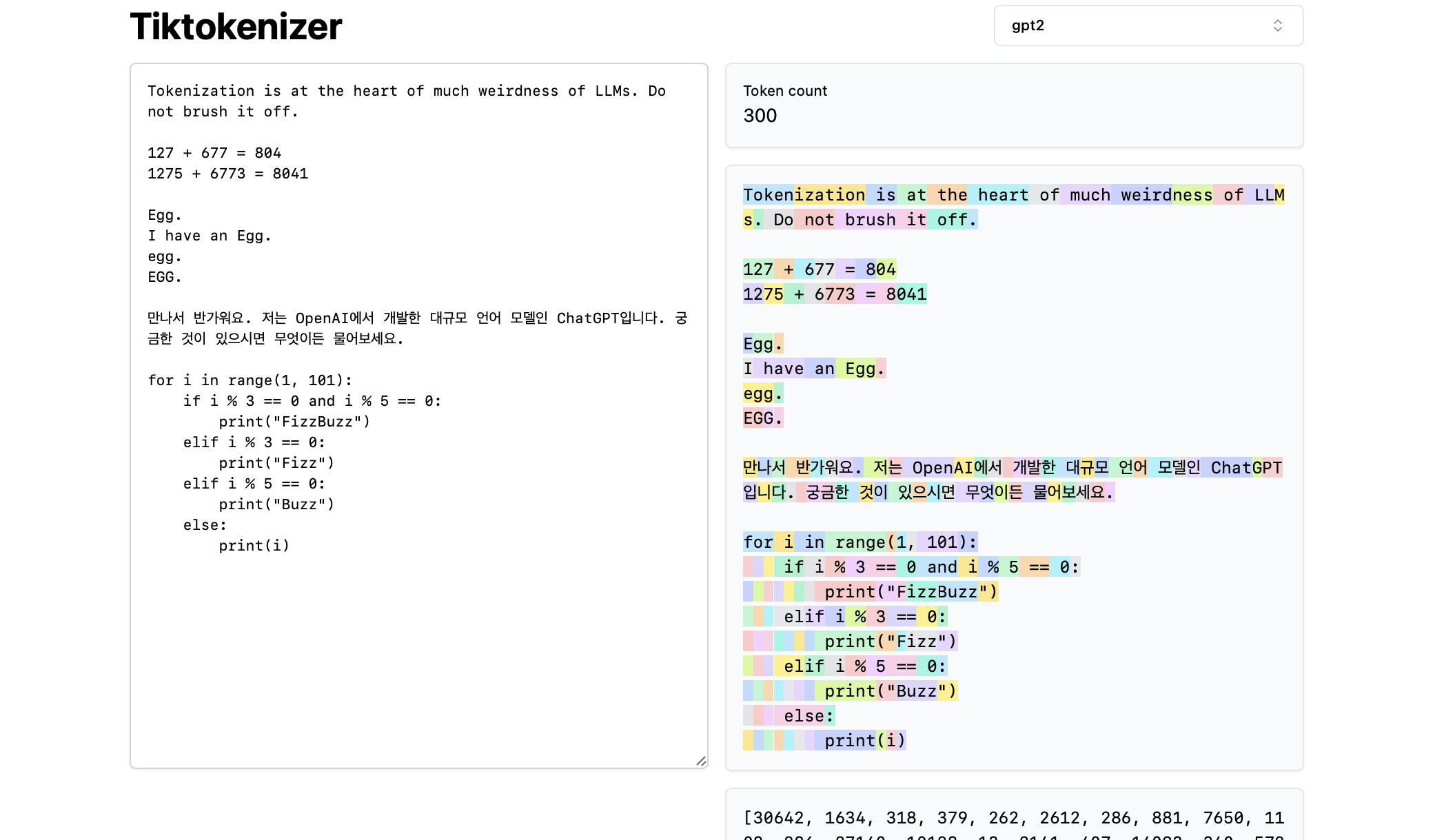
例如,字符串”Tokenization”被编码为令牌30642,紧接着是令牌1634。令牌” is”(注意这里包含三个字符,包括前面的空格,这一点很重要!)的索引是318。要注意的是空格,因为它确实存在于字符串中,必须与所有其他字符一起被令牌化,但为了可视化的清晰通常被省略。您可以在工具的底部切换空格的可视化显示。同样,令牌” at”是379,” the”是262,等等。
接下来,我们来看一个简单的算术例子。这里我们发现,数字可能会被令牌化器以不一致的方式分解。比如,数字127被分解为一个由三个字符组成的单一令牌,而数字677则被分解为两个令牌:令牌” 6″(再次注意前面的空格!)和令牌”77″。我们依赖于大型语言模型来理解这种随意性。模型必须在其参数和训练过程中学习,这两个令牌(” 6″和”77″)实际上结合起来表示数字677。同样,如果LLM想要预测这个加法的结果数字是804,它必须分两步输出:首先发出令牌” 8″,然后是令牌”04″。请注意,所有这些分解看起来都是完全任意的。在下面的示例中,我们看到1275被分解为”12″和”75″,6773实际上是两个令牌” 6″和”773″,而8041则被分解为” 8″和”041″。
(待续…)(TODO:除非我们找到一种方法,能够自动从视频中生成这些内容,否则我们可能会继续这个。)
© 版权声明
文章版权归属AI人工智能助手及承载网站www.tchepai.com所有,未经允许请勿转载。