- 本站
- 百度
- 谷歌
- Bing
- 360搜索
- 搜狗搜索



- AI助手
- AI客户端
- AI绘画
- 图像编辑
- 创意设计
- 视频创作
- 视频加工
- 音频生成
- 语音互动
- AI音乐
- AI写作
- 知识搜索
- 学习辅导
- AI笔记
- 翻译/语言
- 工作效率
- AI制作PPT
- AI数据分析
- AI编程
- AI商业应用
- AI数字人
- AI营销
- 生活娱乐
- AI换脸
- 角色扮演





























































































语音互动





AI音乐














AI写作



























AI笔记












翻译/语言

























AI制作PPT











AI数据分析











AI编程


















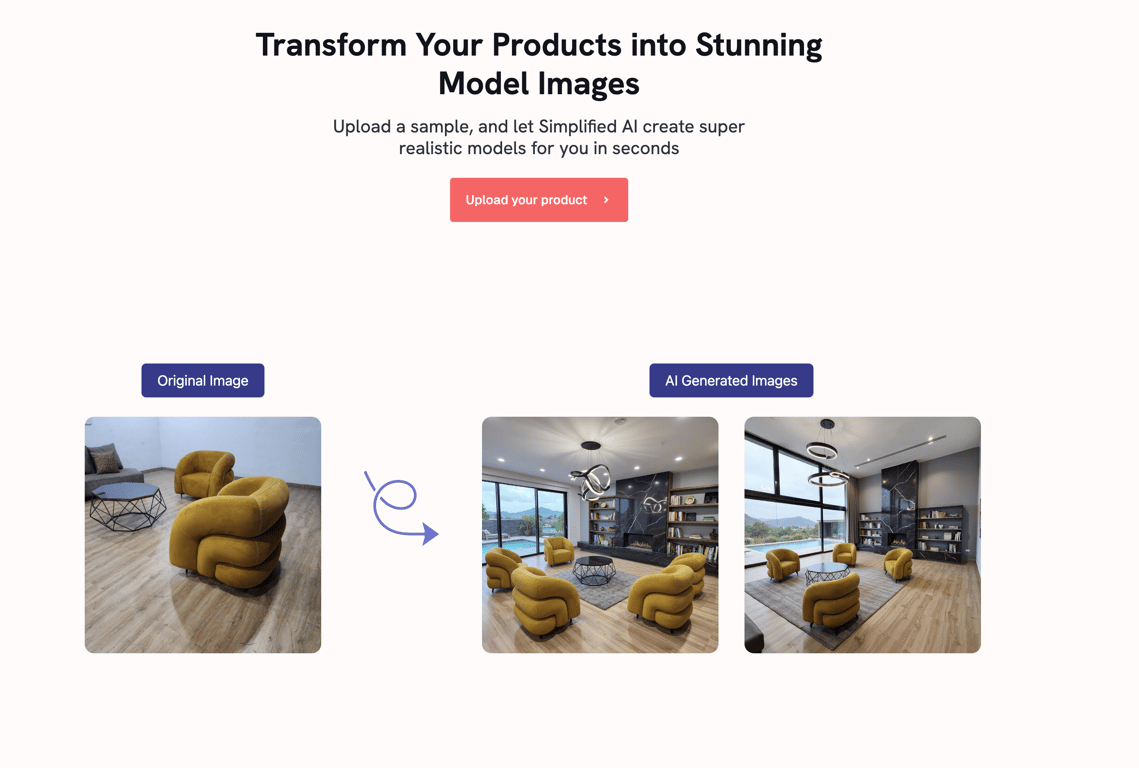


AI数字人



























AI换脸













角色扮演
















桌面智能助手
让AI操作您的电脑。通过RPA(机器人流程自动化)技术,AI可以模拟人类在桌面上的鼠标点击、键盘输入等操作,自动完成重复性任务。

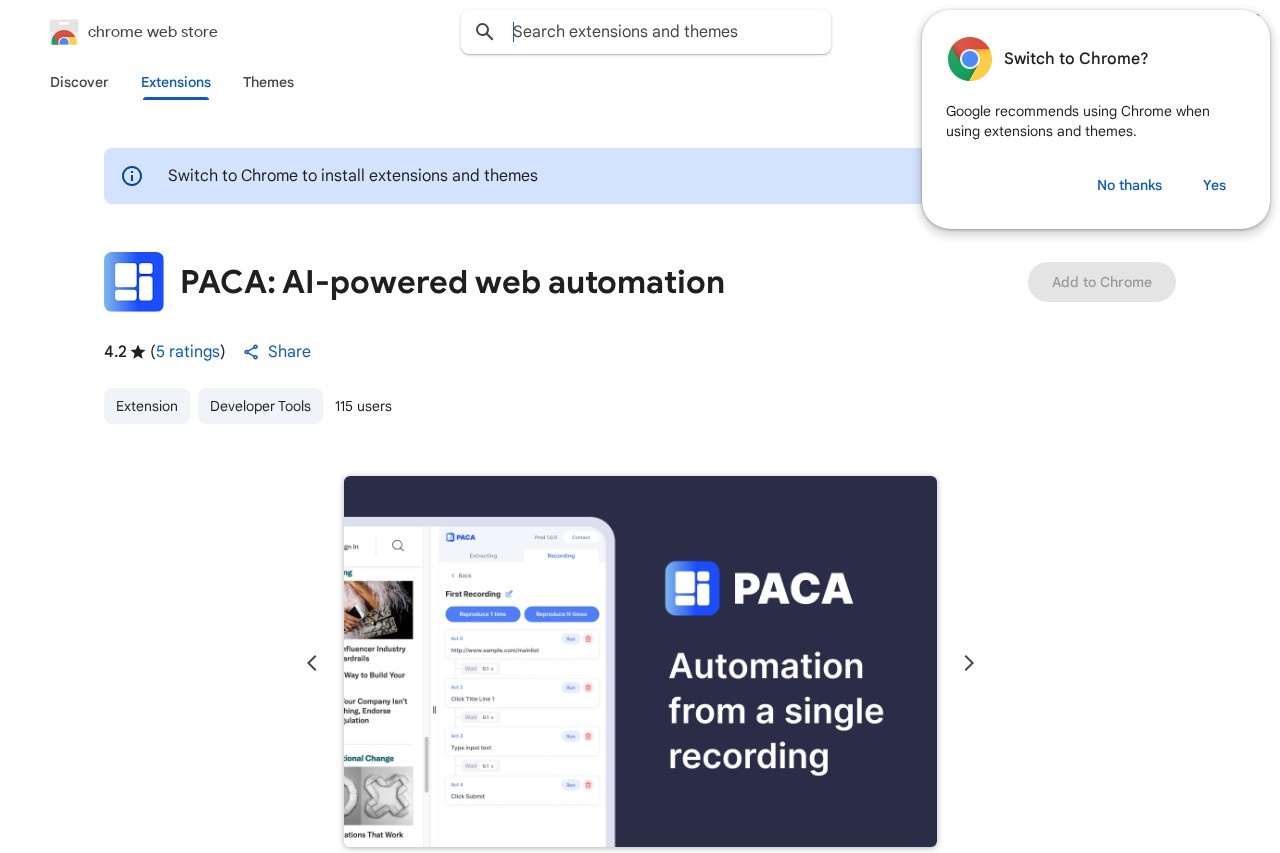

auxmachina.com 提供专业的自动化解决方案和技术服务。