ChatOllama 笔记 | 实现高级RAG的生产化和基于Redis的文档数据库
ChatOllama 是一款基于LLMs的开源聊天机器人。对ChatOllama的详细介绍请点击下方链接。
ChatOllama | 基于Ollama的100%本地RAG应用
ChatOllama 最初的目标是为用户提供一个100%本地RAG应用。
随着其发展,越来越多用户提出有价值的需求。现在,`ChatOllama` 支持多种语言模型包括:
- Ollama 支持的模型
- OpenAI
- Azure OpenAI
- Anthropic
使用 ChatOllama, 用户可以:
- 管理Ollama模型(拉取/删除)
- 管理知识库(创建/删除)
- 与LLMs自由对话
- 管理个人知识库
- 通过个人知识库与LLMs交流
在这篇文章中,我将探讨如何实现高级RAG的生产化。我已经学习了RAG的基本和进阶技巧,但将RAG投入生产仍然有许多需要处理的事项。我将分享在ChatOllama中已经做的工作以及为实现RAG的生产化所做的准备。

ChatOllama | RAG构建化运行
在ChatOllama平台中,我们运用到了LangChain.js来操控RAG流程。在ChatOllama的知识库中,超越于原始RAG的父文档检索器得以运用。让我们深度探究其构架及执行细节。希望对你有所启发。
父文档检索器的实用化
为了让父文档检索器在一个真实产品中运行,我们需理解其核心原理,并为生产目的选取合适的存储元件。
父文档检索器的核心原理
在为检索需求将文档拆分时,经常会遇到冲突的需求:
- 你可能希望文档越小越好,这样它们的嵌入式内容可以最精准地体现它们的含义。如果内容过长,嵌入式信息可能会失去其含义。
- 你也想要足够长的文档,以保证每段内容具备完整的全文环境。
由LangChain.js提供的ParentDocumentRetriever通过将文档拆分为小块来取得这个平衡。每次检索时,它提取小块,然后查找各个小块对应的父文档,返回更大范围的文档。一般来说,父文档会通过doc id与小块相联系。我们稍后会进一步解释其运行方式。
注意,这里的parent document指的是小块的来源文档。
架构
让我们一起来看看父文档检索器的整体架构图。
每个小块会经过处理转变为向量数据,然后存储在向量数据库中。 检索这些小块的过程将如同在原始RAG设置中所做的那样。
父文档(块-1、块-2、……块-m)被分割成更小的部分。 值得注意的是,这里用到了两个不同的文本分割方法:一个较大的用于父文档,另一个较小的用于更小的块。每个父文档都被赋予一个文档ID,然后将此ID作为元数据记录在其对应的小块中。 这确保了每个小块都能通过存储在元数据中的文档ID找到其相应的父文档。
检索父文档的过程与这并不相同。不需要相似性搜索,只需提供文档ID就可以找到其对应的父文档。在这种情况下,一个键-值存储系统就足够胜任。
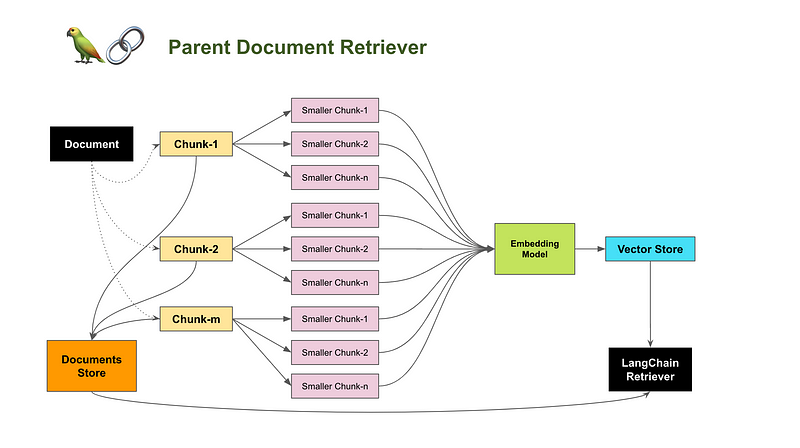
父文档检索器
存储部分
有两种数据需要存储:
- 小规模的向量数据
- 含有其文档ID的父文档的字符串数据
所有主流的向量数据库都是可以使用的。在`ChatOllama`中,我选择了Chroma。
对于父文档数据,我选用了当前最流行并具有高度扩展性的键值存储系统Redis。
LangChain.js缺少的内容
LangChain.js为字节和文档存储提供了大量的集成方式:
以键值对的形式存储数据是快速且高效的,对于LLM应用来说是强大的工具。基础存储库…
支持`IORedis`:
这个示例展示了如何使用RedisByteStore基础存储库集成来设定聊天历史记录的存储。
RedisByteStore中缺少的一部分是collection机制。
在处理不同知识库中的文档时,各个知识库将以一个collection集合的形式进行组织,同一库中的文档将被转化为向量数据并存储在向量数据库如Chroma的某一个collection集合中。
假设我们想要删除一个知识库?我们肯定可以删除Chroma数据库中的一个`collection`集合。但是我们如何按照知识库的维度来清理文档存储呢?因为如RedisByteStore之类的组件并不支持`collection`功能,因此我必须自行实现。
ChatOllama RedisDocStore
在Redis中,并未有名为`collection`的内置功能。开发者通常会通过使用前缀键的方式来实现`collection`功能。下图展示了如何使用前缀来标识不同的集合:
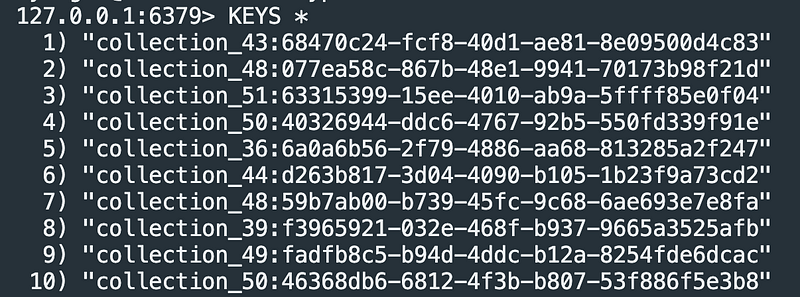
带有前缀的Redis键表示形式
现在我们来看一下,是如何实施以Redis为背景的文档存储功能的。
关键信息:
- 每一个`RedisDocstore`在初始化时都需输入一个`namespace`参数。(当前在namespace和collection的命名可能并未统一)
- 在进行get和set操作时,键都先进行`namespace`处理。
import { Document } from “@langchain/core/documents”;
import { BaseStoreInterface } from “@langchain/core/stores”;
import { Redis } from “ioredis”;
import { createRedisClient } from “@/server/store/redis”;export class RedisDocstore implements BaseStoreInterface<string, Document>
{
_namespace: string;
_client: Redis;constructor(namespace: string) {
this._namespace = namespace;
this._client = createRedisClient();
}serializeDocument(doc: Document): string {
return JSON.stringify(doc);
}deserializeDocument(jsonString: string): Document {
const obj = JSON.parse(jsonString);
return new Document(obj);
}getNamespacedKey(key: string): string {
return `${this._namespace}:${key}`;
}getKeys(): Promise<string[]> {
return new Promise((resolve, reject) => {
const stream = this._client.scanStream({ match: this._namespace + ‘*’ });const keys: string[] = [];
stream.on(‘data’, (resultKeys) => {
keys.push(…resultKeys);
});stream.on(‘end’, () => {
resolve(keys);
});stream.on(‘error’, (err) => {
reject(err);
});
});
}addText(key: string, value: string) {
this._client.set(this.getNamespacedKey(key), value);
}async search(search: string): Promise<Document> {
const result = await this._client.get(this.getNamespacedKey(search));
if (!result) {
throw new Error(`ID ${search} not found.`);
} else {
const document = this.deserializeDocument(result);
return document;
}
}/**
* Adds new documents to the store.
* @param texts An object where the keys are document IDs and the values are the documents themselves.
* @returns Void
*/
async add(texts: Record<string, Document>): Promise<void> {
for (const [key, value] of Object.entries(texts)) {
console.log(`Adding ${key} to the store: ${this.serializeDocument(value)}`);
}const keys = […await this.getKeys()];
const overlapping = Object.keys(texts).filter((x) => keys.includes(x));if (overlapping.length > 0) {
throw new Error(`Tried to add ids that already exist: ${overlapping}`);
}for (const [key, value] of Object.entries(texts)) {
this.addText(key, this.serializeDocument(value));
}
}async mget(keys: string[]): Promise<Document[]> {
return Promise.all(keys.map((key) => {
const document = this.search(key);
return document;
}));
}async mset(keyValuePairs: [string, Document][]): Promise<void> {
await Promise.all(
keyValuePairs.map(([key, value]) => this.add({ [key]: value }))
);
}async mdelete(_keys: string[]): Promise<void> {
throw new Error(“Not implemented.”);
}// eslint-disable-next-line require-yield
async *yieldKeys(_prefix?: string): AsyncGenerator<string> {
throw new Error(“Not implemented”);
}async deleteAll(): Promise<void> {
return new Promise((resolve, reject) => {
let cursor = ‘0’;const scanCallback = (err, result) => {
if (err) {
reject(err);
return;
}const [nextCursor, keys] = result;
// Delete keys matching the prefix
keys.forEach((key) => {
this._client.del(key);
});// If the cursor is ‘0’, we’ve iterated through all keys
if (nextCursor === ‘0’) {
resolve();
} else {
// Continue scanning with the next cursor
this._client.scan(nextCursor, ‘MATCH’, `${this._namespace}:*`, scanCallback);
}
};// Start the initial SCAN operation
this._client.scan(cursor, ‘MATCH’, `${this._namespace}:*`, scanCallback);
});
}
}
您可以将此组件与 ParentDocumentRetriever 无缝结合使用:
retriever = new ParentDocumentRetriever({
vectorstore: chromaClient,
docstore: new RedisDocstore(collectionName),
parentSplitter: new RecursiveCharacterTextSplitter({
chunkOverlap: 200,
chunkSize: 1000,
}),
childSplitter: new RecursiveCharacterTextSplitter({
chunkOverlap: 50,
chunkSize: 200,
}),
childK: 20,
parentK: 5,
});
目前,我们已经拥有高级RAG的可扩展存储解决方案——Parent Document Retriever,同时还有`Chroma`和`Redis`。